GDPR - What do we do about Archive
There's somehow a feeling that GDPR changes what should be done about Personal and Personally Identifying Data that we need not do now. But that isn't really true, For instance, EU citizens have had the right to be forgotten since 2014 after the ECJ decision relating to a Spanish case in 2010. What is happening is that the standards of a complaint, audit and penalty have changed and of course its the penalty which is the real motivator to improve systems. Removing an individual's data from a live system can be painful but perhaps not hard, removing it from archived data looks like it will be expensive, and hard. Apart from other regulatory reasons for keeping data does it mean we have to read and rewrite all archives every time someone asks for their data to be removed? Are we forced to make archived data live to keep it updated?
The key points about the GDPR is auditable governance of data and availability of data for those to whom it belongs. If archived data is not accessible, is not online to the system, it is not available. But does that mean we don't care about archived data? Certainly not.
We absolutely care about data that may reenter the online system, by restoring for example. We care that we should not retain data longer than necessary, and we care that any data we do store, whether online or archived, is safe, protected and we know where it is, where it came from and what we have done with it. The data must remain relevant and the reason for having it must be either statutory, or regulatory, commercial or still required for current processing with a current agreement from the owner of the data. If, however, the archive is really a live system and not a long term archive of data (ie backups which have migrated to long term storage), then it is exactly the same as any other online accessible store of data.
The simple diagram, Lifecycle of Data, shows three domains. These domains must remain separate, the Processes domain cannot have direct access to data in either of the other two domains. In order to cross from one domain to another there must be an auditable permitted process which identifies the source, reason or purpose, who or what transferred it and the destination. In other words the provenance of the data must be maintained and updated as the data flows from one domain to another. Without this we cannot answer a data owner's questions about their own data.
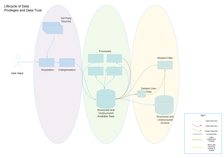
The recording and maintenance of provenance about data does not have to be a separate regulatory layer of services, it can be the existing mechanisms used to transfer data, logging about that transfer with the addition of the capability to abstract information about a particular set of data. It would be better if there was one integrated provenance system documenting the flow and change of data through its life cycle but for the majority of organisations this will be seen as a boil the ocean kind of project. For new projects, startups and any other greenfield opportunity this kind of integration should be considered along with the MVP.
How does this relate to the offline archiving of backups? Just as with Untrusted Data to Processing, Processing to Offline needs to be documented in much the same way. The existing archive and backup system probably provides as much provenance data as is needed in order to discover where a data set is archived, how many versions, when and so on. The Data Retention Policy should determine the duration of these archives. This could become complex if there are multiple constraints applied to different or overlapping subsets of the data. The combination of Financial data from transactions along with account ids, individuals associated with those account ids, for example. The safest course is to apply the statutory or regulatory rules and requirements as the priority constraint on whether the data should be retained, otherwise much shorter periods should be used as the maximum retention.
So the hard question, how do we handle the random requests for a user's personal data to be removed from the system such that it cannot be used, processed or stored elsewhere? The random requests can be batched together for a reasonable period of time and then applied but that involves rewriting possibly all current offline archives with the risk of loss of data that should not be removed. The removal process would also need to be aware of the rules and priorities of data retention and not remove that which is required to be kept even if the user has requested its removal.
This isn't the right way to look at it. The whole point of offline archives is that they are a frozen moment and intended to be complete, rewriting them with missing data even with the provenance data maintained to reflect that would make validating frozen archives a nonsense. Whilst the data is offline it is not available, and must not be made available without going through a similar permissions and provenance process. This would include any allowable availability by a legitimate 3rd party.
A user requiring removal is recorded whether as part of the provenance or as separate metadata, as any identifiers that belong to that individual's data set.
On restoring any offline data this metadata is checked for all identifiers and if there's a match that record or records (or relationship) is not restored.
The provenance data is added for the non-restoration, or restoration as a whole.
If the data is restored in a staged version of the store (which makes sense) then after a complete restoration a new archive, its relation to the original archive recorded as part of its provenance, as the original's own provenance is updated to show it has been replaced.
The original archive can be held intact for its remaining retention time.
As there are vendors claiming GDPR compliance packages there may well be one which has placed a complete provenance system and process around all data movements including offline archival, but I've not found one as yet. Perhaps vendors who believe they do could comment...
Managing the restoration is one of the simpler points of control, if needed in a small organisation a spreadsheet of user requests and manual control of the recovery would work. Yes it would be awful but small organisations are unlikely to receive the volume of a large corporation using social media.
(c) 2017, 2018 G30 Consultants Ltd
All other trademarks and copyright recognised.